According to the author of this article, Lan Che, the author describes in detail the 1) seven important stages of artificial intelligence development; 2) the development of deep learning in artificial intelligence; 3) Finally, the author also puts forward the view of deep learning challenges and future development.
Dave Bowman: Hello, HAL do you read me, HAL? Hal, did you see me?
HAL: Affirmative, Dave, I read you. David, I saw you
Dave Bowman: Open the pod bay doors, HAL. Hal, open the door
HAL: I'm sorry Dave, I'm afraid I can't do that. I'm sorry, David, I can't do this.
~《2001: A Space Odyssey》~
In the past two years, artificial intelligence has become very popular. Not only has technology giant AI achieved breakthroughs in technology and products, but also a number of start-ups have gained the favor of venture capital. Almost every week, they can see reports of investment in startups in related fields. The Chunlei of the time is undoubtedly the battle between artificial intelligence AlphaGo developed by Deepmind and South Korea's Li Shishi. The victory of AiphaGo's big score makes people squint with AI, and it also raises the question of how AI will change our lives. In fact, since the birth of artificial intelligence in the 40s of the last century, it has experienced prosperity and trough again and again. First of all, let's review the development history of artificial intelligence in the past half century.
| Seven chapters in the development of artificial intelligence
The origin of artificial intelligence : Artificial intelligence was born in the 40s-50s of the 20th century. During this time, scientists in the fields of mathematics, engineering, and computers explored the possibility of an artificial brain and tried to define what is the intelligence of the machine. In this context, in 1950, Alan Turing published a paper titled “Can Machines Think?†and it became an epoch-making work. He proposed the famous Turing test to define what a machine has to do with intelligence. He said that as long as 30% of humans The tester could not tell the test subject within 5 minutes and could think that the machine passed the Turing test.
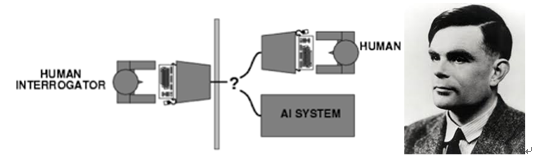
Figure 1: Turing Test; Alan Turing himself
The first golden age of artificial intelligence : The now recognized origin of artificial intelligence is the Dartmouth Conference of 1956, in which computer scientist John McCarthy persuaded the participants to accept “Artificial Intelligenceâ€. More than a decade after the Dartmouth meeting was the first golden age of artificial intelligence. A large number of researchers have been rushing to this new field. Computers have been applied to algebraic applications, geometric theorems, and artificial intelligence projects established by top universities. Obtained large amounts of funding from agencies such as ARPA, and even some researchers believe that machines can quickly replace humans to do everything.
The first trough of artificial intelligence : By the 1970s, due to the bottleneck of computer performance, the increase in computational complexity, and the insufficiency of data, the promises of many projects could not be fulfilled. For example, common computer vision cannot find enough databases at all. Supporting algorithms to train, intelligence will not be able to talk about. Later, the academic community divided artificial intelligence into two types: hard-to-achieve strong artificial intelligence and weak artificial intelligence that could be tried. Strong artificial intelligence can be thought of as human beings and can perform "universal tasks". Weak artificial intelligence deals with single problems. We are still in an era of weak artificial intelligence. The stagnation of many projects has also affected the direction of funding, and AI has participated in the long process. A few years ago the trough.
The advent of expert systems: After the 1970s, the academic community gradually accepted new ideas: artificial intelligence is not only about studying solutions, but also about introducing knowledge. Thus, the expert system was born, it uses digital knowledge to reason, imitate experts in a certain field to solve problems, and "knowledge processing" has become the focus of research on mainstream artificial intelligence. Inspired by the "Knowledge Engineering" presented by the World Congress of Artificial Intelligence in 1977, Japan's fifth-generation computer plan, the British Alver plan, the European Eureka plan, and the U.S. star plan camera were introduced to bring about expert systems. Rapid development led to the emergence of Carnegie Mellon's XCON system and new companies such as Symbolics and IntelliCorp.
The second financial crisis of artificial intelligence: Most of the artificial intelligence projects before the 1990s were funded by government agencies in the research room, and the direction of funding directly affected the development of artificial intelligence. In the mid-1980s, Apple and IBM's desktop performance had exceeded that of general-purpose computers using expert systems, and the landscape of expert systems faded away, and artificial intelligence research once again faced a financial crisis.
After IBM's Deep Blue and Watson: expert system, machine learning has become the focus of artificial intelligence. The purpose is to let the machine have the ability of automatic learning. The algorithm allows the machine to learn the law from a large amount of historical data and make judgments or identify new samples. prediction. At this stage, IBM is undoubtedly the leader of the AI ​​field. In 1996, Deep Blue (based on the exhaustive search tree) defeated the chess world champion Kasparov. In 2011, Watson (based on rules) defeated the human player in the TV quiz show. In particular, the latter involves natural language understanding, which is still a problem, and it becomes a step in the machine's understanding of human language.
The strong rise of deep learning : Deep learning is the second wave of machine learning. In April 2013, MIT Technical Review magazine listed deep learning as the top ten breakthrough technologies in 2013. In fact, deep learning is not a new organism. It is the development of the traditional neural network. There is an identical place between the two. A similar hierarchical structure is adopted. The difference is that deep learning adopts different methods. Training mechanism, with strong expression skills. Traditional neural networks have been a hot area in the field of machine learning. Later, problems such as difficulty in adjusting parameters and slow training speed have faded people’s horizons.
However, an old professor at the University of Toronto, called Geoffrey Hinton, was very persistent in the study of adhering to neural networks, and together with Yoshua Bengio and Yann LeCun, who invented the most widely used deep learning model, the CNN, is feasible. Deep learning program. The iconic thing is that in 2012, Hinton’s students significantly reduced the error rate (ImageNet Classification with Deep Convolutional Neural Networks) in the image classification contest ImageNet, defeating the industrial giant Google and suddenly awakening academic and industrial circles. Not only academic significance, but also attracted a large-scale investment in deep learning in the industrial sector: In 2012 Google Brain trained 1 billion neuron depth network with 16,000 CPU core computing platforms, and automatically identified “Cat†without external intervention. "Hinton's DNN startup was acquired by Google, Hinton personally joined Google, and another big brother LeCun joined Facebook as the director of AI Labs; Baidu established the Deep Learning Institute, led by Wu Enda, who had led Google Brain." . Not only have technology giants increased their investment in AI, a large number of start-up companies have emerged from the wave of deep learning, making the field of artificial intelligence bustling.
| The main engine of artificial intelligence: Deep learning
Machine learning and development is divided into two stages, originated in shallow learning 1920s (Shallow Learning) and only in recent years fire up the deep learning (Deep Learning) of the last century. In the shallow learning algorithm, the first to be invented is the back propagation of the neural network. Why is it referred to as the shallow layer? The main reason is that the training model at that time contained only one hidden layer (in the middle). The shallow model of the layer), the shallow model has a great weakness is the finite parameters and the calculation unit, the feature expression ability is weak.
In the 1990s, the academic community proposed a series of shallow machine learning models, including the popular support vector machine Support Vector Machine, Boosting, etc. These models have a certain increase in efficiency and accuracy compared to the neural network until Many colleges and universities in the year before 2010 were using fashionable SVM and other algorithms, including the author himself (at that time as a machine learning professional Xiao Shuo, the study is the automatic classification of Twitter text, using SVM), mainly because This type of shallow model algorithm is simple in theoretical analysis, and the training method is relatively easy to grasp. In this period, the neural network is relatively quiet, and it is difficult to see the research based on neural network algorithm in the top academic conference.
But in fact, people later discovered that even if training more data and adjusting parameters, the accuracy of the recognition seems to be a bottleneck that can not go up, and many times also need to manually identify the training data, costing a lot of manpower, the five major steps in machine learning have Feature perception, image preprocessing, feature extraction, feature screening, prediction and recognition, of which the first four items have to be personally designed (the author finally decided to change course after a hellish torture of machine learning). During this period, our persistent Professor Hinton has been studying algorithms for multiple hidden layer neural networks. In fact, the multi hidden layer is an in-depth version of the shallow neural network, trying to use more neurons to express features, but why There are three reasons for this hardship: Â
1. The back propagation of error in BP algorithm decays with the increase of hidden layer; the optimization problem can only reach the local optimal solution in many cases.
2. When the model parameters increase, there is a high requirement for the amount of training data. In particular, the inability to provide huge identification data will only lead to excessive complexity;
3. There are many parameters of multi-hidden layer structure, and the scale of training data is large, and it needs to consume a lot of computing resources.
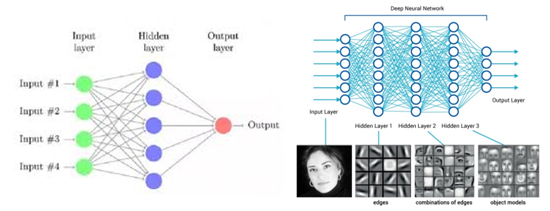
Figure 2: Traditional neural networks and multiple hidden layer neural networks
In 2006, Hinton and his student RR Salakhutdinov published an article in Science (Reducing the dimensionality of data with neural networks). They successfully trained multilayer neural networks and changed the entire machine learning landscape, although only 3 Pages of paper but now it seems worth a thousand words. This article has two main points: 1) The multi-hidden layer neural network has more powerful learning ability and can express more features to describe the object; 2) When training deep neural networks, it can be achieved through pre-training. Realization, the old professor's design of the Autoencoder network can quickly find a good overall advantage, using unsupervised methods to separate each layer of network training, and then fine-tuning.
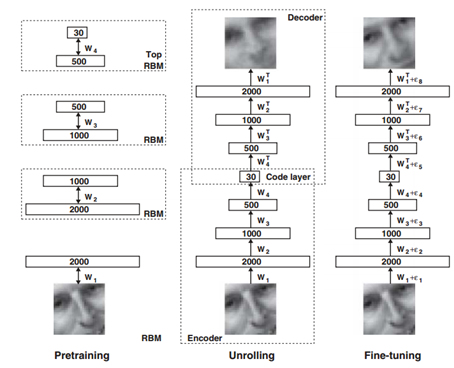
Figure 3: Image and Training, Encoding, Decoding, Fine Tuning
From Figure 3 we can see that the depth network is pre-trained layer by layer to obtain the output of each layer; and the encoder and decoder are introduced at the same time to train through the error after the original input and encoding → re-decoding. Steps are unsupervised training processes; finally, there are identification samples, which are fine tuned by supervised training. The advantage of layer-by-layer training is that the model is in a position close to global optimum for better training results.
These are the famous deep learning frameworks put forward by Hinton in 2006. When we actually use deep learning networks, we will inevitably encounter Convolutional Neural Networks (CNN). The principle of CNN is to imitate the excitement structure of human neurons: some individual neurons in the brain can only react when there are edges in specific directions. The popular feature extraction method is CNN. For example, when we look very close to a face picture (assuming it can be very, very close), only a part of the neurons are activated at this time. We can only see the pixels on the human face. At the level, when we pull the distance a little bit, other parts of the neuron will be activated, and we can also observe the line of the face → pattern → local → face, the whole process is to obtain high-level features step by step. .
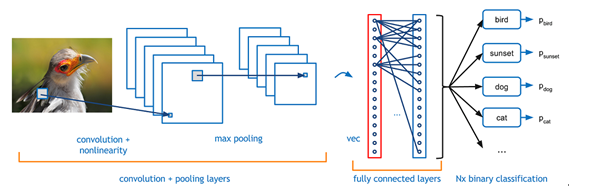
Figure 4: Basic Complete Deep Learning Process
The "deep" (deep hidden layers) of deep learning, the benefits are obvious - strong ability to express features, capable of representing a large amount of data; pretraining is unsupervised training, saving a lot of human identification work; compared to traditional neural networks, through Layer-by-layer training reduces the difficulty of training, such as signal attenuation. In many academic fields, deep learning often results in a 20-30% improvement in performance compared to shallow learning algorithms. This drives researchers to find that the New World is generally flocking to the field of deep learning, which makes it difficult to send papers about using deep learning. Now.
| An important area of ​​development for deep learning
Deep learning has made great progress in image, sound, and semantic recognition first. Especially in the field of image and sound, the recognition rate has been greatly improved compared to traditional algorithms. In fact, it is also very easy to understand. Deep learning is to imitate people and the brain to perceive outsiders. The world's algorithms, and the most direct external natural signal than the image, sound and text (non-semantic).
Image recognition : The image is the earliest field of deep learning. Daniel Yann LeCun started research on convolutional neural networks as early as 1989 and achieved some results in image recognition on a small scale (handwritten words), but it is rich in pixels. There was no breakthrough in the picture until the breakthrough of Hinton and his students on ImageNet in 2012, which made the recognition accuracy a big step forward. In 2014, the computer vision research group led by Professor Tang Xiaoou of the Chinese University of Hong Kong developed a deep learning model called DeepID, which obtained 99.15% of the LFW (Labored Faces in the Wild) database for face recognition using a very wide range of benchmarks. Recognition rate, the recognition rate of naked eye on LFW is 97.52%, and deep learning has exceeded the human eye recognition in academic research level.
Of course, when dealing with real-life face recognition, it is still unsatisfactory. For example, the face is not clear, lighting conditions, partial occlusion and other factors will affect the recognition rate. Therefore, the combination of machine learning and manual confirmation in actual operations is more appropriate. There are numerous domestic companies for face recognition, including Face++, Goosen, Sensetime, Linkface, and FlySearch. All of them are in front, and they have deep data accumulation in real environments or vertical segmentation. In the field of emotion recognition based on facial feature recognition technology, reading technology and Facethink (Facethink is an early investment project of Angels Bay) are a few start-up companies that have entered the field.
Speech Recognition : Speech recognition has long been modeled using a mixture of Gaussian models, and has been a monopoly of modeling for a long time. However, despite the fact that it reduces the error rate of speech recognition, it still faces commercial-grade applications. Difficulties, that is, in practically noisy environments do not reach the available levels. Until the advent of deep learning, the recognition error rate has dropped by more than 30% on the best basis in the past, reaching the level of commercial availability. Dr. Yu Dong and Dr. Deng Li from Microsoft were the earliest practitioners of this breakthrough. Together with Hinton, they first introduced deep learning to speech recognition and achieved success. Due to the maturity of voice recognition algorithms, the recognition rates of HKUST, Yun Zhisheng, and Si Bisi are not much different from each other in universal recognition. In the promotion of the HKUST, XF is a pioneer, from military to civilian use, including mobile Internet and car networking. Smart homes are widely involved.
Natural language processing (NLP) : Even though deep learning currently does not achieve results in the field of image recognition or speech recognition in the NLP field, statistical models are still the mainstream of NLP. Keywords, keyword matching, and algorithms are first extracted through semantic analysis. The sentence function is determined (calculation of the nearest sentence that is closest to the sentence), and the user output is finally provided from the database prepared in advance. Obviously, this is obviously not smart enough. It can only be regarded as an implementation of the search function, but lacks real language skills. Apple’s Siri, Microsoft’s Xiao Bing, Turing robots, Baidu’s secretive and other giants are all working hard in the field of smart chat robots. The application scenarios are mainly customer service in China (even if customers hate machine customers, they all hope to be able to directly In connection with human services, I don't think there is yet a very mature product on the market. Xiao Bing is still very interesting in many competitors, her idea is "you just chat with me," while other competitors are focused on certain segments but still face the need for a common chat system in the segmented areas. , Personally think that Xiao Bing after a few years of data accumulation and algorithm improvement is a certain advantage to come to the fore.
Why deep learning progresses slowly in the NLP field : For speech and images, the elements (contours, lines, speech frames) can clearly reflect the entity or phoneme without preprocessing, and can be easily applied to neural networks. Identify the job. Semantic recognition differs greatly: First, a sentence of text is preprocessed by the brain, not a natural signal; second, the similarity between words does not mean that their meanings are similar, and the meaning of words is also ambiguous when simple words are combined. In particular, Chinese, for example, “Doesn't expect it,†refers to a person who never thought of it, or unexpectedly did not expect it, or the name of a movie.) Dialogue requires contextual language The understanding of the environment requires that the machine has the ability to reason; the human language is flexible in expression, and many exchanges rely on knowledge. It's interesting that deep learning built on the human brain recognition mechanism works poorly on text signals processed by our human brain. Fundamentally speaking, the current algorithm is still weak artificial intelligence, can help humans perform automatic (recognition) quickly, but still can not understand the matter itself.
Explore the challenges and direction of the depth of learning |
Thanks to the improvement of computing power and the emergence of big data, deep learning has achieved remarkable results in the field of computer vision and speech recognition. However, we have also seen some limitations of deep learning that need to be resolved: Â
1. Deep learning has achieved good results in the academic field, but business-to-business activities have been of limited help because deep learning is a mapping process that maps from input A to output B, and in corporate activities I Already have such A→B pairings, why do we still need machine learning to predict? It is still very difficult for the machine to find this pairing relationship or make predictions in the data itself.
2. The lack of theoretical foundation is a problem that plagues researchers. For example, AlphaGo won this game, and it is difficult for you to understand how it wins and what its strategy is. In this sense, deep learning is a black box. In the process of actually training the network, it is also a black box: how many hidden layers do the neural network need to train, and how many effective parameters are needed? There is no good theoretical explanation. . I believe that many researchers spent a lot of time on boring parameter tuning when building multi-layer neural networks.
3. Deep learning requires a large number of training samples. Due to the multi-layer network structure of deep learning, which has strong feature expression capabilities, the parameters of the model will also increase. If the training sample is too small, it is difficult to achieve, and a large amount of marked data is needed to avoid overfitting ( Overfitting) does not represent the entire data well.
4. In the above chapter on deep learning in NLP applications, it is also mentioned that the current model still lacks understanding and reasoning capabilities.
Therefore, the next development direction of deep learning will also involve the solution of the above issues. Hinton, LeCun, and Bengio's three AI leaders once mentioned in the co-authored Deep Learning:
(https://~hinton/absps/NatureDeepReview.pdf)
Unsupervised learning. Although supervised learning performs well in deep learning, overwhelming the effect of unsupervised learning in pre-training, but both human and animal learning are unsupervised learning. We perceive the world to be our own observations, so to be more Close to the human brain learning model, unsupervised learning needs to be better developed.
2. Strengthen learning. Enhanced learning refers to learning from the external environment to behavior mapping, and discovering optimal behavior through trial and error based on reward functions. Since the amount of data is increasing in practice, it is very important to be able to learn effective data and make corrections in the new data. Depth + reinforcement learning can provide a rewarding feedback mechanism for machine autonomous learning (typical case is AlphaGo ). Â
3. Understand natural language. The old professors said: Let the machine read the language quickly! Â
4. Transfer learning. The application of big data training model migration to tasks with a small amount of effective data, that is, the knowledge learned to effectively solve different but related issues, this matter is very sexy, but the problem is that the migration process has been trained The model is self biased, so efficient algorithms are needed to eliminate these biases. Fundamentally speaking, it is to let the machine have the ability to learn new knowledge quickly like humans.
Since the deep learning was published by Hinton in Science, in just a short period of less than 10 years, revolutionary advances in the fields of vision and speech have been triggered, triggering an upsurge of artificial intelligence. Although there are still many unsatisfactory places, there is still a long distance from strong artificial intelligence. It is currently the closest algorithm to the human brain's operating principle. I believe that in the future, with the improvement of algorithms and the accumulation of data, even hardware aspects With the advent of human brain neuron material, deep learning will further intelligentize the machine.
Finally, we ended this article with a quote by Mr. Hinton: "It has been obvious since the 1980s that backpropagation through deep autoencoders would be very effective for nonlinear dimensionality reduction, provided that computers were fast enough, data sets were big enough , and the initial weights were close enough to a good solution. All three conditions are now satisfied.†(We have known since the 1980s that if there is a computer fast enough, the data is large enough, the initial weight value is perfect enough, based on automatic depth The back propagation algorithm of the encoder is very effective. Now, all three are available.)
Lei Feng Network (search "Lei Feng Network" public number attention) Note: The article is authorised by the author, if you need to reprint please contact the original author. Lancher is from Angel Bay Ventures, focusing on investment in artificial intelligence and robotics. He studied and worked in Japan for ten years. He deeply studies AI robot business and loves black technology. He welcomes entrepreneurs of all types of AI and robotics to hook up. WeChat hongguangko- Sir.
Polycrystalline Solar Panel,160W Polysilicon Solar Panel,160W Solar Panel,Goal Zero Solar
Zhejiang G&P New Energy Technology Co.,Ltd , https://www.solarpanelgp.com